La syntaxe de XML est relativement simple. Elle est constituée de quelques règles pour l'écriture d'une entête et des balises pour structurer les données. Ces règles sont très similaires à celles du langage HTML utilisé pour les pages WEB mais elles sont, en même temps, plus générales et plus strictes. Elles sont plus générales car les noms des balises sont libres. Elles sont aussi plus strictes car elles imposent qu'à toute balise ouvrante corresponde une balise fermante.
Le langage XML est un format orienté texte. Un document XML est simplement une suite de caractères respectant quelques règles. Il peut être stocké dans un fichier et/ou manipulé par des logiciel en utilisant un codage des caractères. Ce codage précise comment traduire chaque caractère en une suite d'octets réellement stockés ou manipulés. Les différents codages possibles et leurs incidences sur le traitement des documents sont abordés plus loin dans ce chapitre. Comme un document XML est seulement du texte, il peut être écrit comme l'exemple ci-dessous.
On commence par donner un premier exemple de document XML comme il
peut être écrit dans un fichier bibliography.xml.
Ce document représente une bibliographie de livres sur XML. Il a été
tronqué ci-dessous pour réduire l'espace occupé. Ce document contient
une liste de livres avec pour chaque livre, le titre, l'auteur, l'éditeur
(publisher en anglais), l'année de parution, le numéro ISBN et
éventuellement une URL.
<?xml version="1.0" encoding="iso-8859-1"?><!-- Time-stamp: "bibliography.xml 3 Mar 2008 16:24:04" -->
<!DOCTYPE bibliography SYSTEM "bibliography.dtd" >
<bibliography>
<book key="Michard01" lang="fr">
<title>XML langage et applications</title> <author>Alain Michard</author> <year>2001</year> <publisher>Eyrolles</publisher> <isbn>2-212-09206-7</isbn> <url>http://www.editions-eyrolles/livres/michard/</url> </book> <book key="Zeldman03" lang="en"> <title>Designing with web standards</title> <author>Jeffrey Zeldman</author> <year>2003</year> <publisher>New Riders</publisher> <isbn>0-7357-1201-8</isbn> </book> ... </bibliography>

| Entête XML avec la version |
| Commentaire délimité par les chaînes de caractères
|
| Déclaration de DTD externe dans le fichier
|
| Balise ouvrante de l'élément racine
|
| Balise ouvrante de l'élément |
| Balise fermante de l'élément racine
|
Un document XML est une suite de caractères. Les caractères qui
peuvent être utilisés sont ceux définis par la norme Unicode ISO
10646 aussi appelée UCS pour Universal Character
Set. Cette norme recense tous les caractères des langues
connues et tous les symboles utilisés dans les différentes disciplines.
Elle nomme tous ces caractères et symboles et leur attribue un code sur
32 bits (4 octets) appelé simplement code Unicode ou
point de code dans la terminologie Unicode. Dans la
pratique, tous les points de code attribués à des caractères se situent
dans l'intervalle de 0 à 0x10FFFF et ils utilisent donc au plus 21 bits.
Cette longueur maximale ne sera pas dépassée avant longtemps car il reste
encore de nombreux points de code non attribués dans cet intervalle pour
des usages futurs. Unicode peut être vu comme un catalogue de tous les
caractères disponibles. Un caractère dont le point de code est
n est désigné par
U+ où le nombre
nn est écrit en hexadécimal. L'écriture
hexadécimale de n n'est pas préfixée du
caractère 'x' car c'est implicite après les deux
caractères 'U+'. Le caractère Euro '€' est, par
exemple, désigné par U+20AC car son point de code est
8364 = 0x20AC. Le sous-ensemble des caractères Unicode dont les points
de code tiennent sur 16 bits (2 octets), c'est-à-dire entre 0 et 65535 =
0xFFFF est appelé BMP pour Basic Multilingual Plane.
Il couvre largement la très grande majorité des langues usuelles et les
symboles les plus courants.
Les cinq caractères '<'
U+2C, '>'
U+2E, '&'
U+26, '''
U+27 et '"'
U+22 ont une signification particulière dans les
documents XML. Les deux caractères '<' et
'>' servent à délimiter les balises, ainsi que les commentaires et les instructions de traitement. Le caractère
'&' marque le début des références aux entités générales. Pour
introduire ces caractères dans le contenu du document, il faut utiliser
des sections littérales ou les
entités prédéfinies.
Les caractères ''' et '"'
servent également de délimiteurs, en particulier pour les valeurs des
attributs. Dans ces cas,
il faut encore avoir recours aux entités prédéfinies pour les
introduire.
Le traitement XML des caractères d'espacement est simple dans un
premier temps. Chaque caractère d'espacement est équivalent à un espace
et plusieurs espaces consécutifs sont encore équivalents à un seul
espace. C'est le comportement habituel des langages de programmation
classiques. Dans un second temps, le traitement des caractères
d'espacement par une application est commandé par l'attribut xml:space. Les
caractères d'espacement sont l'espace ' '
U+20, la tabulation U+09
('\t' en notation du langage C), le saut de ligne
U+0A ('\n' en C) et le retour
chariot U+0D ('\r' en C).
Les fins de lignes sont normalisées par l'analyseur lexical
(parser en anglais). Ceci signifie que les
différentes combinaisons de fin de ligne sont remplacées par un seul
caractère U+0A avant d'être transmises à
l'application. Cette transformation garantit une indépendance vis à vis
des différents systèmes d'exploitation. Les combinaisons remplacées par
cette normalisation sont les suivantes.
la suite des deux caractères U+0D
U+0A |
la suite des deux caractères U+0D
U+85 |
le caractère U+85 appelé Next
Line |
le caractère U+2028 appelé Line
Separator |
le caractère U+0D non suivi de
U+0A ou U+85 |
Les deux caractères U+85 et
U+2028 ne peuvent être correctement décodés qu'après
la déclaration de l'encodage des caractères par l'entête. Leur usage dans l'entête
est donc déconseillé.
Les identificateurs sont utilisés en XML pour nommer différents
objets comme les éléments, les attributs, les instructions de
traitement. Ils servent aussi à identifier certains éléments par
l'intermédiaire des attributs de type ID. XML distingue deux types
d'identificateurs: les jetons et les noms
XML. La seule différence est que les noms XML doivent
commencer par certains caractères particuliers. Dans la terminologie
XML, les jetons sont appelés NMTOKEN pour
name token.
Les caractères autorisés dans les identificateurs sont tous les
caractères alphanumériques, c'est-à-dire les lettres minuscules
[a-z], majuscules [A-Z] et les
chiffres [0-9] ainsi que le tiret '-' U+2D, le point '.' U+2E, les deux points
':' U+3A et le tiret
souligné '_' U+5F.
Un jeton est une suite quelconque de ces
caractères. Un nom XML est un jeton qui, en outre,
commence par une lettre [a-zA-Z], le caractère
':' ou le caractère '_'. Les deux
caractères '-' et '.' ainsi que
les chiffres ne peuvent pas apparaître au début des noms. Il n'y a pas,
a priori, de limite à la taille des identificateurs mais certains
logiciels peuvent en imposer une dans la pratique.
Le caractère ':' est réservé à l'utilisation
des espaces de noms. De fait, il
ne peut apparaître qu'une seule fois pour séparer un préfixe du nom
local dans les noms des éléments et des attributs. Les espaces de noms
amènent à distinguer les noms ayant un caractère ':',
appelés noms qualifiés et les autres, appelés par
opposition noms non qualifiés.
Les noms commençant par les trois lettres xml
en minuscule ou majuscule, c'est-à-dire par une chaîne de
[xX][mM][lL] sont réservés aux usages internes de
XML. Ils ne peuvent pas être utilisés librement dans les documents mais
ils peuvent cependant apparaître pour des utilisations spécifiques
prévues par la norme. Les noms commençant par xml:
comme xml:base font partie de l'espace de noms XML.
Quelques exemples d'identificateurs sont donnés ci-dessous.
La norme XML 1.1 prévoit que tout caractère Unicode de catégorie
lettre peut apparaître dans les identificateurs. Il est, par exemple,
possible d'avoir des noms d'éléments avec des caractères accentués. Il
est cependant conseillé de se limiter aux caractères ASCII de
[a-zA-Z] pour assurer une meilleure compatibilité.
Beaucoup de logiciels ne gèrent pas les autres caractères dans les
identificateurs.
Chaque caractère possède un point de code sur 32 bits mais un document ne contient pas directement ces points de code des caractères. Ce codage serait inefficace puisque chaque caractère occuperait 4 octets. Chaque document utilise un codage pour écrire les points de code des caractères. Il existe différents codages dont le codage par défaut UTF-8. Certains codages permettent d'écrire tous les points de code alors que d'autres permettent seulement d'écrire un sous-ensemble comme le BMP. Le codage utilisé par un document est indiqué dans l'entête de celui-ci. Les principaux codages utilisés par les documents XML sont décrits ci-dessous.
- US-ASCII
Ce codage permet uniquement de coder les points de code de 0 à 0x7F des caractères ASCII.
- UCS-4 ou UTF-32
Chaque caractère est codé directement par son point de code sur quatre octets. Ce codage permet donc de coder tous les caractères Unicode.
- UCS-2
Chaque caractère est codé par son point de code sur deux octets. Ce codage permet donc uniquement de coder les caractères du BMP.
- UTF-16
Ce codage coïncide essentiellement avec UCS-2 à l'exception de la plage de 2048 positions de 0xD800 à 0xDFFF qui permet de coder des caractères en dehors du BMP dont le point de code utilise au plus 20 bits. L'exclusion de cette plage ne pose aucun problème car elle ne contient aucun point de code attribué à un caractère. Un point de code ayant entre 17 et 20 bits est scindé en deux blocs de 10 bits répartis sur une paire de mots de 16 bits. Le premier bloc de 10 bits est préfixé des 6 bits
110110pour former un premier mot de 16 bits et le second bloc de 10 bits est préfixé des 6 bits110111pour former un second mot de 16 bits.Représentation UTF-16 Signification xxxxxxxx xxxxxxxx2 octets codant 16 bits 110110zz zzxxxxxx4 octets codant 20 bits 110111xx xxxxxxxxyyyy xxxxxxxx xxxxxxxx où zzzz = yyyy-1 Tableau 2.1. Codage UTF-16
Le symbole de l'Euro '€'
U+20AC, est, par exemple, codé par les deux octetsx20 xAC=00100000 10101100puisqu'il fait partie du BMP. Le symbole de la croche '𝅘𝅥𝅮'U+1D160est codé par les 4 octetsxD8 x34 xDD x60=11011000 0011010011011101 01100000.- UTF-8
Ce codage est le codage par défaut de XML. Chaque caractère est codé sur un nombre variable de 1 à 4 octets. Les caractères de l'ASCII sont codés sur un seul octet dont le bit de poids fort est 0. Les caractères en dehors de l'ASCII utilisent au moins deux octets. Le premier octet commence par autant de 1 que d'octets dans la séquence suivis par un 0. Les autres octets commencent par 10. Ce codage peut uniquement coder des points de code ayant au maximum 21 bits mais tous les points de code attribués ne dépassent pas cette longueur.
Représentation UTF-8 Signification 0xxxxxxx1 octet codant 7 bits 110xxxxx10xxxxxx2 octets codant 8 à 11 bits 1110xxxx10xxxxxx10xxxxxx3 octets codant 12 à 16 bits 11110xxx10xxxxxx10xxxxxx10xxxxxx4 octets codant 17 à 21 bits Tableau 2.2. Codage UTF-8
Le symbole de l'Euro '€'
U+20AC, est, par exemple, codé par les trois octetsxE2 x82 xAC=111000101000001010101100. Le symbole de la croche '𝅘𝅥𝅮'U+1D160est, quant à lui, codé par les 4 octetsxF0 x9D x85 xA0=11110000100111011000010110100000. Ce codage a l'avantage d'être relativement efficace pour les langues européennes qui comportent beaucoup de caractères ASCII. Il est, en revanche, peu adapté aux langues asiatiques dont les caractères nécessitent 3 octets alors que 2 octets sont suffisants avec UTF-16.- ISO-8859-1 (appelé Latin-1)
Chaque caractère est codé sur un seul octet. Ce codage coïncide avec l'ASCII pour les points de code de 0 à 0x7F. Les codes de 0x80 à 0xFF sont utilisés pour d'autres caractères (caractères accentués, cédilles, …) des langues d'Europe de l'ouest.
- ISO-8859-15 (appelé Latin-9 ou Latin-0)
Ce codage est une mise à jour du codage ISO-8859-1 dont il diffère uniquement en 8 positions. Les caractères '€', 'Š', 'š', 'Ž', 'ž', 'Œ', 'œ' et 'Ÿ' remplacent les caractères
'¤'U+A4,'¦'U+A6,'¨'U+A8,'´'U+B4,'¸'U+B8,'¼'U+BC,'½'U+BDet'¾'U+BEmoins utiles pour l'écriture des langues européennes. Le symbole de l'Euro'€'U+20AC, est, par exemple, codé par l'unique octetxA4=10100100.
Le tableau suivant donne la suite d'octets pour le mot
Hétérogène pour quelques codages classiques. Comme
les points de code de x00 à xFF d'Unicode coïncident avec le codage des
caractères de ISO-8859-1, le codage en UTF-16 est obtenu en insérant un
octet nul 00 avant chaque octet du codage en ISO-8859-1. Le codage en
UTF-32 est obtenu en insérant dans le codage en UTF-16 deux octets nuls
avant chaque paire d'octets.
| Codage | Séquence d'octets en hexadécimal pour
Hétérogène |
|---|---|
| UTF-8 | 48 C3 A9 74 C3 A9 72 6F 67 C3 A8 6E 65 |
| ISO-8859-1 | 48 E9 74 E9 72 6F 67 E8 6E 65 |
| UTF-16 | 00 48 00 E9 00 74 00 E9
00 72 … 00 E8 00 6E 00 65 |
| UTF-32 | 00 00 00 48 00 00 00 E9 00 00 00 74
… 00 00 00 65 |
Tableau 2.3. Comparaison des codages
Les logiciels manipulant des documents XML doivent obligatoirement
gérer les codages UTF-8 et UTF-16. Les autres codages sont facultatifs.
Il est essentiel que le codage d'un document soit indiqué dans l'entête du document. Si un
navigateur interprète, par exemple, la suite d'octets du codage UTF-8 du
mot Hétérogène comme un codage en ISO-8859-1, il
affiche la chaîne
Hétérogène.
Bien que certains codages ne permettent pas de coder tous les
points de code, il est néanmoins possible d'insérer n'importe quel
caractère Unicode en donnant explicitement son point de code avec une
des deux syntaxes suivantes. Ces syntaxes peuvent être utilisées pour
n'importe quel point de code même si celui-ci peut être écrit avec le
codage du document. Elles sont, en particulier, pratiques lorsque les
éditeurs de texte affichent mal certains caractères. Les deux syntaxes
prennent les formes &# ou point de code
décimal;&#x. Le caractère Euro
'€' peut par exemple être inséré par
point
de code hexadécimal;€ ou €. Pour
ces deux syntaxes, c'est le point de code du caractère qui est écrit en
décimal ou en hexadécimal et non pas sa transcription dans le codage du
document.
Pour les codages non basés sur les octets comme UTF-16 ou UCS-2, il est important de savoir dans quel ordre sont placés les deux octets de poids fort et de poids faible d'un mot de 16 bits. Il existe deux modes appelés gros-boutiste et petit-boutiste (big endian et little endian en anglais). Dans le mode gros-boutiste, l'octet de poids fort est placé avant l'octet de poids faible alors que dans le mode petit-boutiste, l'octet de poids fort est placé après l'octet de poids faible.
Afin de savoir quel est le mode utilisé dans un document XML, le
document commence par le caractère U+FEFF. Ce
caractère est appelé espace insécable de largeur
nulle (zero-width no-break space en
anglais) mais il a été remplacé, pour cet emploi, par le caractère
U+2060. Il est maintenant uniquement utilisé comme
marque d'ordre des octets (Byte order mark ou
BOM en anglais). Cette marque est sans ambiguïté
car il n'existe pas de caractère de point de code 0xFFFE. Le tableau
suivant récapitule les séquences des premiers octets d'un document en
fonction du codage et du mode gros-boutiste ou petit-boutiste. Les
valeurs 0x3C, 0x3F et 0x78 sont les points de code des trois premiers
caractères '<', '?' et 'x' de l'entête.
| Codage | Mode | Séquence d'octets en hexadécimal |
|---|---|---|
| UTF-8 sans BOM | 3C 3F 78 | |
| UTF-8 avec BOM | EF BB BF 3C 3F 78 | |
| UTF-16 ou UCS-2 | gros-boutiste | FE FF 00 3C 00 3F |
| UTF-16 ou UCS-2 | petit-boutiste | FF FE 3C 00 3F 00 |
| UTF-32 | gros-boutiste | 00 00 FE FF 00 00 00 3C |
| UTF-32 | petit-boutiste | FE FF 00 00 3C 00 00 00 |
Tableau 2.4. Marques d'ordre des octets
Bien que la marque d'ordre des octets puisse être mise dans un document codé en UTF-8, celle-ci est inutile et il est déconseillé de la mettre. La marque d'ordre des octets ne peut pas être mise dans un document codé en ISO-8859-1.
Certaines ligatures comme le caractère 'œ'
U+153 sont considérées par Unicode comme un seul
caractère plutôt que comme la fusion des deux caractères
'oe'. Il s'ensuit que les deux mots
cœur et coeur sont, a priori,
considérés comme distincts. Ce problème est résolu par l'utilisation de
collations lors du traitement des documents. Une
collation est une collection de règles qui établissent des équivalences
entre des caractères ou des suites de caractères. Une collation peut,
par exemple, déclarer que le caractère 'œ'
U+153 est équivalent aux deux caractères
'oe' ou que la lettre 'ß'
U+DF est équivalente aux deux lettres
'ss'. Une collation établit aussi l'ordre des
caractères utilisé pour l'ordre lexicographique. Elle peut, par
exemple, déclarer que le caractère 'é' se place entre
les caractères 'e' et 'f'. La
collation par défaut est basée sur les points de code des caractères.
Le caractère 'é' U+E9 se trouve,
pour cette collation, après le caractère 'z'
U+7A et le mot zèbre est donc
avant le mot étalon dans l'ordre
lexicographique.
Le même caractère peut avoir plusieurs points de code. Cette
ambiguïté provient du fait qu'Unicode a été construit en fusionnant
plusieurs codages et qu'il tente de rester compatible avec chacun d'eux.
Le caractère 'µ' est en même temps le caractère
U+B5 qui provient de Latin-1 et le caractère
U+3BC qui provient du bloc des caractères grecs.
D'autres caractères peuvent avoir un point de code mais peuvent, en même
temps, correspondre à une suite de plusieurs points de code. Le
caractère 'ö' est, par exemple, le caractère
U+F6 mais il correspond également à la suite
U+6F U+308 formée du caractère
'o' suivi du caractère spécial tréma
'¨' U+308. Ce codage multiple
conduit à des problèmes, en particulier pour la comparaison des chaînes
de caractères. Pour palier à ce problème, Unicode introduit des
normalisations qui transforment les différents
codages en un codage canonique. La normalisation la plus standard est
la normalisation C. Celle-ci transforme, par exemple, la suite de
caractères U+6F U+308 en le
caractère 'ö' U+F6. La
normalisation d'une chaîne de caractères peut être obtenue avec la
fonction XPath normalize-unicode().
XML et toutes les technologies autour de XML font un grand usage des URI et plus particulièrement des URL. Ceux-ci sont, par exemple, employés pour référencer des documents externes comme des DTD ou pour identifier des espaces de noms. Les URL sont bien connues car elles sont utilisées au quotidien pour naviguer sur le WEB. La terminologie XML distingue également les URI et les URN. Les significations exactes de ces trois termes dans la terminologie XML sont les suivantes.
- URI
Uniform Resource Identifier
- URL
Uniform Resource Locator
- URN
Uniform Resource Name
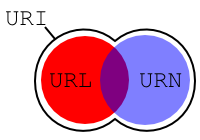
La notion la plus générale est celle d'URI. Les URI comprennent
les URL et les URN même si certains URI peuvent être simultanément des
URL et des URN. Les liens entre ces différents termes sont illustrés à
la figure. Un URI est un
identifiant qui permet de désigner sans ambiguïté un document ou plus
généralement une ressource. Cet identifiant doit donc être unique de
manière universelle. Une URL identifie un document en spécifiant un
mécanisme pour le retrouver. Elle est composée d'un protocole suivi
d'une adresse permettant de récupérer le document avec le protocole. Un
URN est, au contraire, un nom donné à un document indépendamment de la
façon d'accéder au document. Un exemple typique d'URN est l'URN formé à
partir du numéro ISBN d'un livre comme
urn:isbn:978-2-7117-2077-4. Cet URN identifie le
livre Langages formels, calculabilité et complexité
mais n'indique pas comment l'obtenir.
La syntaxe générale des URI prend la forme
scheme:identscheme est un schéma
d'URI et où ident est un identifiant obéissant
à une syntaxe propre au schéma scheme. Chaque
schéma définit un sous-espace des URI. Dans le cas d'une URL, le schéma
est un protocole d'accès au document comme http,
sip, imap ou
ldap. Le schéma utilisé pour tous les URN est
urn. Il est généralement suivi de l'identificateur
d'un espace de noms comme isbn. Des exemples d'URI
sont donnés ci-dessous. Les deux derniers URI de la liste sont des
URN.
http://www.omega-one.org/~carton/ sftp://carton@omega-one.org tel:+33-1-57-27-92-54 sip:0957279254@freephonie.net file://home/carton/Enseignement/XML/Cours/XSLT urn:oasis:names:tc:docbook:dtd:xml:docbook:5.1 urn:publicid:-:W3C:DTD+HTML+4.0:EN
Dans la pratique, la plupart des URI utilisées sont des URL et les deux termes peuvent pratiquement être considérés comme synonymes.
Un URI appelé URI de base est souvent attaché à un document ou à un fragment d'un document XML. Cet URI est généralement une URL. Il sert à résoudre les URL contenues dans le fragment de document, qu'elles soient relatives ou absolues. Cette résolution consiste à combiner l'URL de base avec ces URL pour obtenir des URL absolues qui permettent de désigner des documents externes.
Pour comprendre comment une URL de base se combine avec une URL, il faut d'abord comprendre la structure d'une URL. La description donnée ci-dessous se limite aux aspects indispensables pour appréhender la résolution des URL. Chaque URL se décompose en trois parties.
- Protocole d'accès
Une URL commence obligatoirement par le nom d'un protocole d'accès suivi du caractère
':'. Les principaux protocoles sonthttp,https,ftpetfile.- Adresse Internet
Le protocole est suivi d'une adresse Internet qui commence par les deux caractères
'//'. Cette adresse est absente dans le cas du protocolefile.- Chemin d'accès
L'URL se termine par un chemin d'accès dans l'arborescence des fichiers. Ce chemin se décompose lui-même en le nom du répertoire et le nom du fichier. Ce dernier est formé de tous les caractères après le dernier caractère
'/'.
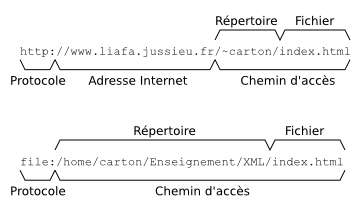
La combinaison d'une URL de base base avec une
autre URL url pour former une URL complète est
réalisée de la façon suivante qui dépend essentiellement de la forme de
la seconde URL url.
Si l'URL
urlest elle-même une URL complète qui commence par un protocole, le résultat de la combinaison est l'URLurlsans tenir compte de l'URLbase.Si l'URL
urlest un chemin absolu commençant par le caractère'/', le résultat est obtenu en remplaçant la partie chemin de l'URLbasepar l'URLurl. L'URLurlest donc ajoutée après la partie adresse Internet de l'URLbase.Si l'URL
urlest un chemin relatif ne commençant pas par le caractère'/', le résultat est obtenu en remplaçant le nom du fichier de l'URLbasepar l'URLurl. Le chemin relatif est donc concaténé avec le nom du répertoire.
Les exemples ci-dessous illustrent les différents cas. On suppose
que l'URL base est fixée égale à l'URL
http://www.somewhere.org/Teaching/index.html. Pour chacune
des valeurs de l'URL url, on donne la valeur de l'URL
obtenue par combinaison de l'URL base avec l'URL
url.
url=""(chaîne vide)http://www.somewhere.org/Teaching/index.htmlurl="XML/chapter.html"(chemin relatif)http://www.somewhere.org/Teaching/XML/chapter.htmlurl="XML/XPath/section.html"(chemin relatif)http://www.somewhere.org/Teaching/XML/XPath/section.htmlurl="/Course/section.html"(chemin absolu)http://www.somewhere.org/Course/section.htmlurl="http://www.elsewhere.org/section.html"(URL complète)http://www.elsewhere.org/section.html
Il y a, en français, l'orthographe et la grammaire. La première est constituée de règles pour la bonne écriture des mots. La seconde régit l'agencement des mots dans une phrase. Pour qu'une phrase en français soit correcte, il faut d'abord que les mots soient bien orthographiés et, ensuite, que la phrase soit bien construite. Il y aurait encore le niveau sémantique mais nous le laisserons de côté. XML a également ces deux niveaux. Pour qu'un document XML soir correct, il doit d'abord être bien formé et, ensuite, être valide. La première contrainte est de nature syntaxique. Un document bien formé doit respecter certaines règles syntaxiques propres à XML qui sont explicitées dans ce chapitre. Il s'agit, en quelque sorte, de l'orthographe d'XML. La seconde contrainte est de nature structurelle. Un document valide doit respecter un modèle de document. Un tel modèle décrit de manière rigoureuse comment doit être organisé le document. Un modèle de documents peut être vu comme une grammaire pour des documents XML. La différence essentielle avec le français est que la grammaire d'XML n'est pas figée. Pour chaque application, il est possible de choisir la grammaire la plus appropriée. Cette possibilité d'adapter la grammaire aux données confère une grande souplesse à XML. Il existe plusieurs langages pour écrire des modèles de document. Les DTD (Document Type Description), héritées de SGML, sont simples mais aussi assez limitées. Elles sont décrites au chapitre suivant. Les schémas XML sont beaucoup plus puissants. Ils sont décrits dans un autre chapitre.
Un document XML est généralement contenu dans un fichier texte dont
l'extension est .xml. Il peut aussi être réparti en
plusieurs fichiers en utilisant les entités externes ou XInclude. Les fichiers contenant
des documents dans un dialecte XML peuvent avoir une autre extension qui
précise le format. Les extensions pour les schémas XML, les feuilles de style XSLT, les dessins en SVG sont, par exemple, .xsd,
.xsl et .svg.
Un document XML est, la plupart du temps, stocké dans un fichier mais il peut aussi être dématérialisé et exister indépendamment de tout fichier. Il peut, par exemple, exister au sein d'une application qui l'a construit. Une chaîne de traitement de documents XML peut produire des documents intermédiaires qui sont détruits à la fin. Ces documents existent uniquement pendant le traitement et sont jamais mis dans un fichier.
La composition globale d'un document XML est immuable. Elle comprend toujours les constituants suivants.
- Prologue
Il contient des déclarations facultatives.
- Corps du document
C'est le contenu même du document.
- Commentaires et instructions de traitement
Ceux-ci peuvent apparaître partout dans le document, dans le prologue et le corps.
Le document se découpe en fait en deux parties consécutives qui sont le prologue et le corps. Les commentaires et les instructions de traitement sont ensuite librement insérés avant, après et à l'intérieur du prologue et du corps. La structure globale d'un document XML est la suivante.
<?xml ... ?> ⌉ Prologue ... ⌋ <root-element> ⌉ ... | Corps </root-element> ⌋
Dans l'exemple donné au début de ce chapitre, le prologue comprend
les trois premières lignes du fichier. La première ligne est l'entête
XML et la deuxième est simplement un commentaire utilisé par Emacs pour
mémoriser le nom du fichier et sa date de dernière modification. La
troisième ligne est la déclaration d'une DTD externe contenue dans le
fichier bibliography.dtd. Le corps du document
commence à la quatrième ligne du fichier avec la balise ouvrante
<bibliography>. Il se termine à la dernière
ligne de celui-ci avec la balise fermante
</bibliography>.
Le prologue contient deux déclarations facultatives mais fortement conseillées ainsi que des commentaires et des instructions de traitement. La première déclaration est l'entête XML qui précise entre autre la version de XML et le codage du fichier. La seconde déclaration est la déclaration du type du document (DTD) qui définit la structure du document. La déclaration de type de document est omise lorsqu'on utilise des schémas XML ou d'autres types de modèles qui remplacent les DTD. La structure globale du prologue est la suivante. Dans le prologue, tous les caractères d'espacement sont interchangeables mais l'entête est généralement placée, seule, sur la première ligne du fichier.
<?xml ... ?> ] Entête XML ⌉
<!DOCTYPE root-element [ ⌉ | Prologue
... | DTD |
]> ⌋ ⌋
Les différentes parties du prologue sont détaillées dans les sections suivantes.
L'entête utilise une syntaxe <?xml ... ?>
semblable à celle des instructions de
traitement bien qu'elle ne soit pas véritablement une instruction
de traitement. L'entête XML a la forme générale suivante.
<?xml version="..." encoding="..." standalone="..."?>
L'entête doit se trouver au tout début du document. Ceci signifie
que les trois caractères '<?xml' doivent être les
cinq premiers caractères du document, éventuellement précédés d'une
marque d'ordre des octets.
Cette entête peut contenir trois attributs
version, encoding et
standalone. Il ne s'agit pas véritablement d'attributs car ceux-ci sont
réservés aux éléments mais la syntaxe identique justifie ce petit abus
de langage. Chaque attribut a une valeur délimitée par une paire
d'apostrophes ''' ou une paire de
guillemets '"'.
L'attribut version précise la
version d'XML utilisée. Les valeurs possibles actuellement sont
1.0 ou 1.1. L'attribut
encoding précise le codage des caractères
utilisé dans le fichier. Les principales valeurs possibles sont
US-ASCII, ISO-8859-1,
UTF-8, et UTF-16. Ces noms de
codage peuvent aussi être écrits en minuscule comme
iso-8859-1 ou utf-8. L'attribut
standalone précise si le fichier est autonome,
c'est-à-dire s'il existe des déclarations externes qui affectent le
document. La valeur de cet attribut peut être yes ou
no et sa valeur par défaut est no.
Les déclarations externes peuvent provenir d'une DTD externe où d'entités paramètres. Elles
peuvent affecter le contenu du document en donnant, par exemple, des
valeurs par défaut à
des attributs. La valeur de l'attribut standalone
influence également la prise en compte des caractères d'espacement dans
les contenus purs lors de
la validation par une DTD.
L'attribut version est obligatoire et
l'attribut encoding l'est aussi dès que le codage des
caractères n'est pas le codage par défaut UTF-8. Quelques
exemples d'entête XML sont donnés ci-dessous.
<?xml version="1.0"?> <?xml version='1.0' encoding='UTF-8'?> <?xml version="1.1" encoding="iso-8859-1" standalone="no"?>
Lorsqu'un document est scindé en plusieurs fragments dans différents fichiers inclus par des entités externes ou par XInclude, chacun des fragments peut commencer par une entête. L'intérêt est de pouvoir spécifier un codage des caractères différent.
La déclaration de type définit la structure du document. Elle
précise en particulier quels éléments peut contenir chacun des éléments.
Cette déclaration de type peut prendre plusieurs formes suivant que la
définition du type est interne, c'est-à-dire incluse dans le document ou
externe. Elle a la forme générale suivante qui utilise le mot clé
DOCTYPE.
<!DOCTYPE ... >
La forme précise de cette déclaration est explicitée au chapitre consacré aux DTD.
Le corps du document est constitué de son contenu qui est organisé de façon hiérarchique à la manière d'un système de fichiers à l'exception qu'aucune distinction n'est faite entre fichiers et répertoires. L'unité de cette organisation est l'élément. Chaque élément peut contenir du texte simple, comme un fichier, d'autres éléments, comme un répertoire, ou encore un mélange des deux.
Comme dans une arborescence de fichiers, il y a un élément appelé élément racine qui contient l'intégralité du document.

Un élément est formé d'une balise ouvrante,
d'un contenu et de la balise fermante correspondante. La
balise ouvrante prend la forme
< formée du
caractère name>'<'
U+3C, du nom name de
l'élément et du caractère '>'
U+3E. Des attributs peuvent éventuellement
être ajoutés entre le nom et le caractère '>'. La
balise fermante prend la forme
</ formée des
deux caractères name>'</'
U+3C et U+2F, du nom
name de l'élément et du caractère
'>'. Les noms des éléments sont des noms XML quelconques. Ils ne sont pas
limités à un ensemble fixé de noms prédéfinis comme en HTML. Le
contenu d'un élément est formé de tout ce qui se
trouve entre la balise ouvrante et la balise fermante (cf. figure). Il peut être constitué de
texte, d'autres éléments, de commentaires et d'instructions de traitement.
Dans la balise ouvrante, le caractère '<' doit être immédiatement suivi du nom de
l'élément. En revanche, il peut y avoir des espaces entre le nom et le
caractère '>'. La balise fermante ne
peut pas contenir d'espace.

Lorsque le contenu est vide, c'est-à-dire lorsque la balise
fermante suit immédiatement la balise ouvrante, les deux balises peuvent
éventuellement se contracter en une seule balise de la forme
< formée du
caractère name/>'<', du nom
name et des deux caractères '/>'. Cette contraction est à privilégier
lorsque l'élément est déclaré vide par
une DTD.

Comme chaque élément possède une balise ouvrante et une balise
fermante, les balises vont nécessairement par paire. À toute balise
ouvrante correspond une balise fermante et inversement. L'imbrication
des balises doit, en outre, être correcte. Si deux éléments
tag1 et tag2 ont un contenu
commun, alors l'un doit être inclus dans l'autre. Autrement dit, si la
balise ouvrante <tag2> se trouve entre les deux
balises <tag1> et
<tag1/>, alors la balise fermante
</tag2> doit aussi se trouver entre les deux
balises <tag1> et
<tag1/> (cf. figure).
<parent> <sibling1> ... </sibling1> <sibling2> ... </sibling2> <self> <child1> ... <desc1></desc1> ... <desc2></desc2> ... </child1> <child2> ... </child2> <child3> ... <desc3><desc4> ... </desc4></desc3> ... </child3> </self> <sibling3> ... </sibling3> </parent>
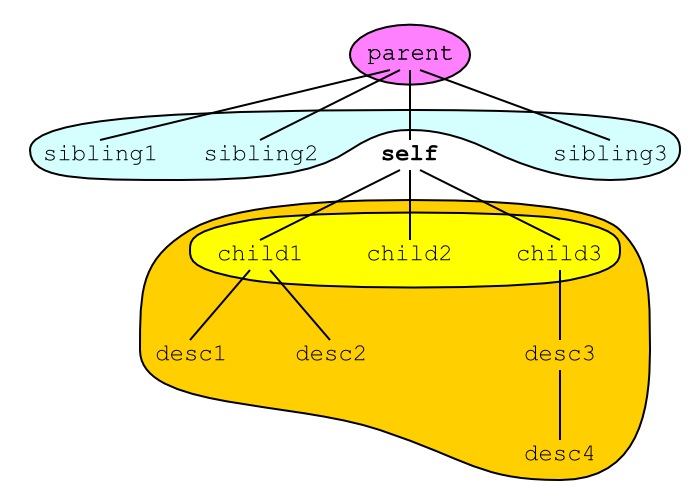
Dans l'exemple ci-dessus, le contenu de l'élément
self s'étend de la balise ouvrante
<child1> jusqu'à la balise fermante
</child3>. Ce contenu comprend tous les
éléments child1, child2 et
child3 ainsi que les éléments
desc1, desc2,
desc3 et desc4. Tous les éléments
qu'il contient sont appelés descendants de
l'élément self. Parmi ces descendants, les éléments
child1, child2 et
child3 qui sont directement inclus dans
self sans élément intermédiaire sont appelés les
enfants de l'élément self.
Inversement, l'élément parent qui contient
directement self est appelé le
parent de l'élément self. Les
autres éléments qui contiennent l'élément self sont
appelés les ancêtres de l'élément
self. Les autres enfants
sibling1, sibling2 et
sibling3 de l'élément parent sont
appelés les frères de l'élément
self. Ces relations de parenté entre les éléments
peuvent être visualisées comme un arbre généalogique (cf. figure).
Tout le corps du document doit être compris dans le contenu d'un
unique élément appelé élément racine. Le nom de
cet élément racine est donné par la déclaration de type de document si
celle-ci est présente. L'élément bibliography est
l'élément racine de l'exemple donné au début du chapitre.
... ] Commentaires et instructions de traitement ⌉ <root-element> ] Balise ouvrante de l'élément racine | Corps ... ⌉ Éléments, commentaires et | du ... ⌋ instructions de traitement | document </root-element> ] Balise fermante de l'élément racine | ... ] Commentaires et instructions de traitement ⌋
Les caractères spéciaux '<',
'>' et '&' ne peuvent pas être inclus directement
dans le contenu d'un document. Ils peuvent être inclus par
l'intermédiaire des entités
prédéfinies.
Il est souvent fastidieux d'inclure beaucoup de caractères
spéciaux à l'aide des entités. Les sections
littérales, appelées aussi sections
CDATA en raison de leur syntaxe,
permettent d'inclure des caractères qui sont recopiés à l'identique.
Une section littérale commence par la chaîne de caractères
'<![CDATA[' et se termine par la chaîne ']]>'. Tous les caractères qui se trouvent
entre ces deux chaînes font partie du contenu du document, y compris les
caractères spéciaux.
<![CDATA[Contenu avec des caractères spéciaux <, > et & ]]>
Une section CDATA ne peut pas contenir la chaîne de caractères
']]>' qui permet à l'analyseur lexical de détecter
la fin de la section. Il est en particulier impossible d'imbriquer des
sections CDATA.
Les balises ouvrantes peuvent contenir des
attributs associés à des valeurs. L'association de
la valeur à l'attribut prend la forme
attribute='value'attribute="value"attribute et
value sont respectivement le nom et la valeur
de l'attribut. Chaque balise ouvrante peut contenir zéro, une ou
plusieurs associations de valeurs à des attributs comme dans les
exemples génériques suivants.
<tagattribute="value"> ... </tag> <tagattribute1="value1"attribute2="value2"> ... </tag>
Voici ci-dessous d'autres exemples concrets de balises ouvrantes avec des attributs. Ces exemples sont respectivement tirés d'un document XHTML, d'un schéma XML et d'une feuille de style XSLT.
<body background='yellow'>
<xsd:element name="bibliography" type="Bibliography">
<a href="#{$node/@idref}">
Lorsque le contenu de l'élément est vide et que la balise ouvrante et la balise fermante sont contractées en une seule balise, celle-ci peut contenir des attributs comme la balise ouvrante.
<hr style="color:red; height:15px; width:350px;" /> <xsd:attribute name="key" type="xsd:NMTOKEN" use="required"/>
Le nom de chaque attribut doit être un nom XML. La valeur d'un attribut peut
être une chaîne quelconque de caractères délimitée par une paire
d'apostrophes ''' ou une paire de
guillemets '"'. Elle peut contenir
les caractères spéciaux '<', '>', '&',
''' et '"' mais ceux-ci doivent
nécessairement être introduits par les entités prédéfinies. Si la
valeur de l'attribut est délimitée par des apostrophes
''', les guillemets '"'
peuvent être introduits directement sans entité et inversement.
<xsl:value-of select="key('idchapter', @idref)/title"/>
<xsl:if test='@quote = "'"'>
Comme des espaces peuvent être présents dans la balise après le
nom de l'élément et entre les attributs, l'indentation est libre pour
écrire les attributs d'une balise ouvrante. Aucun espace ne peut
cependant séparer le caractère '=' du
nom de l'attribut et de sa valeur. Il est ainsi possible d'écrire
l'exemple générique suivant.
<tagattribute1="value1"attribute2="value2" ...attributeN="valueN"> ... </tag>
L'ordre des attributs n'a pas d'importance. Les attributs d'un élément doivent avoir des noms distincts. Il est donc impossible d'avoir deux occurrences du même attribut dans une même balise ouvrante.
Le bon usage des attributs est pour les meta-données plutôt que
les données elles-mêmes. Ces dernières doivent être placées de
préférence dans le contenu des éléments. Dans l'exemple suivant, la
date proprement dite est placée dans le contenu alors que l'attribut
format précise son format. La norme ISO 8601
spécifie la représentation numérique de la date et de l'heure.
<date format="ISO-8601">2009-01-08</date>
C'est une question de style de mettre les données dans les
attributs ou dans les contenus des éléments. Le nom complet d'un
individu peut, par exemple, être réparti entre des éléments
firstname et surname regroupés
dans un élément personname comme dans l'exemple
ci-dessous.
<personname id="I666"> <firstname>Gaston</firstname> <surname>Lagaffe</surname> </personname>
Les éléments firstname et
surname peuvent être remplacés par des attributs de
l'élément personname comme dans l'exemple ci-dessous.
Les deux solutions sont possibles mais la première est
préférable.
<personname id="I666" firstname="Gaston" surname="Lagaffe"/>
Il existe quatre attributs particuliers
xml:lang, xml:space,
xml:base et xml:id qui font partie
de l'espace de noms XML. Lors
de l'utilisation de schémas, ces attributs peuvent être déclarés en
important le schéma à
l'adresse http://www.w3.org/2001/xml.xsd.
Contrairement à l'attribut xml:id, les trois
autres attributs xml:lang,
xml:space et xml:base s'appliquent
au contenu de l'élément. Pour cette raison, la valeur de cet attribut
est héritée par les enfants et, plus généralement, les descendants.
Ceci ne signifie pas qu'un élément dont le père a, par exemple, un
attribut xml:lang a également un attribut
xml:lang. Cela veut dire qu'une application doit
prendre en compte la valeur de l'attribut xml:lang
pour le traitement l'élément mais aussi de ses descendants à
l'exception, bien sûr, de ceux qui donnent une nouvelle valeur à cet
attribut. Autrement dit, la valeur de l'attribut
xml:lang à prendre en compte pour le traitement d'un
élément est celle donnée à cet attribut par l'ancêtre (y compris
l'élément lui-même) le plus proche. Pour illustrer le propos, le
document suivant contient plusieurs occurrences de l'attribut
xml:lang. La langue du texte est, à chaque fois,
donnée par la valeur de l'attribut xml:lang le plus
proche.
<?xml version="1.0" encoding="iso-8859-1" standalone="no"?>
<book xml:lang="fr">
<title>Livre en Français</title>
<chapter>
<title>Chapitre en Français</title>
<p>Paragraphe en Français</p>
<p xml:lang="en">Paragraph in English</p>
</chapter>
<chapter xml:lang="en">
<title>Chapter in English</title>
<p xml:lang="fr">Paragraphe en Français</p>
<p>Paragraph in English</p>
</chapter>
</book>
Ce qui a été expliqué pour l'attribut xml:lang
vaut également pour deux autres attributs xml:space
et xml:base. C'est cependant un peu différent pour
l'attribut xml:base car la valeur à prendre en
compte doit être calculée à partir de toutes les valeurs des attributs
xml:base des ancêtres.
L'attribut xml:lang est utilisé pour décrire
la langue du contenu de l'élément. Sa valeur est un code de langue sur
deux ou trois lettres de la norme ISO 639 (comme
par exemple en, fr,
es, de, it,
pt, …). Ce code peut être suivi d'un code de
pays sur deux lettres de la norme ISO 3166
séparé du code de langue par un caractère tiret '-'. L'attribut xml:lang est
du type xsd:language
qui est spécialement prévu pour cet attribut.
<p xml:lang="fr">Bonjour</p> <p xml:lang="en-GB">Hello</p> <p xml:lang="en-US">Hi</p>
Dans le document donné en exemple au début du chapitre, chaque
élément book a un attribut lang.
Ce n'est pas l'attribut xml:lang qui a été utilisé
car celui-ci décrit la langue des données contenues dans l'élément
alors que l'attribut lang décrit la langue du livre
référencé.
L'attribut xml:space permet d'indiquer à une
application le traitement des caractères d'espacement.
Les deux valeurs possibles de cet attribut sont default et preserve.
L'analyseur lexical transmet les caractères d'espacement aux
applications sans les modifier. La seule transformation effectuée est
la normalisation des fins de lignes. Il appartient ensuite aux
applications de traiter ces caractères de façon appropriée. La plupart
d'entre elles considèrent de façon équivalente les différents
caractères d'espacement. Ceci signifie qu'une fin de ligne est vue
comme un simple espace. Plusieurs espaces consécutifs sont aussi
considérés comme un seul espace. Ce traitement est généralement le
traitement par défaut des applications. Si l'attribut
xml:space a la valeur preserve,
l'application doit, au contraire, respecter les différents caractères
d'espacement. Les fins de ligne sont préservées et les espaces
consécutifs ne sont pas confondus. L'attribut
xml:space intervient, en particulier, dans le
traitement des espaces par XSLT.
À chaque élément d'un document XML est associée une URI appelée URI de
base. Celle-ci est utilisée pour résoudre les URL des
entités externes, qui peuvent être, par exemple des fichiers XML ou des
fichiers multimédia (images, sons, vidéos). Dans le fragment de document
XHTML ci-dessous, l'élément img référence un fichier
image element.png par son attribut
src.
<img src="element.png" alt="Élément"/>
L'attribut de xml:base permet de préciser
l'URI de base d'un élément. Par défaut, l'URI de base d'un élément est
hérité de son parent. L'URI de base de la racine du document est
appelée URI de base du document. Elle est souvent
fixée par l'application qui traite le document mais elle peut aussi
provenir d'un attribut xml:base de l'élément racine.
Lorsque le document provient d'un fichier local, c'est souvent le
chemin d'accès à celui-ci dans l'arborescence des fichiers, comme
file:/home/carton/Teaching/XML/index.html. Lorsque le
document est, au contraire, téléchargé, l'URI de base du document est
l'adresse Internet de celui-ci comme
http://www.omega-one.org/~carton/index.html.
Pour chaque élément, l'attribut xml:base
permet de fixer une URI de base de façon absolue ou, au contraire, de
la construire à partir de l'URI de base du parent. Le comportement
dépend de la forme de la valeur de l'attribut. La valeur est combinée
avec l'URI de base du parent en suivant les règles de combinaison de
celles-ci. L'attribut xml:base est de type
xsd:anyURI.
L'attribut xml:base est indispensable pour
réaliser des inclusions de fichiers externes avec XInclude lorsque ces fichiers
sont situés dans un répertoire différent de celui réalisant
l'inclusion.
Le document suivant illustre les différents cas pour la combinaison d'une URI avec une adresse. Pour chacun des éléments, l'URI de base est donnée.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <book xml:base="http://www.somewhere.org/Teaching/index.html">
|
|
|
|
|
|
|
|
|
|
L'URI de base d'un élément est retournée par la fonction XPath
base-uri().
L'attribut xml:id est de type xsd:ID. Il permet d'associer un identificateur
à tout élément indépendamment de toute DTD ou de tout schéma.
Comme les applications qui traitent les documents XML ne prennent
pas en compte les modèles de document, sous forme de DTD ou de schéma,
elles ne peuvent pas déterminer le type des attributs. Il leur est en
particulier impossible de connaître les attributs de type ID qui permettent d'identifier et de référencer
les éléments. L'attribut xml:id résout ce problème
puisqu'il est toujours du type xsd:ID
qui remplace le type ID dans les schémas XML.
Les commentaires sont délimités par les chaînes de caractères
'<!--' et '-->' comme en
HTML. Ils ne peuvent pas contenir la chaîne '--'
formée de deux tirets '-' et ils ne peuvent donc pas
être imbriqués. Ils peuvent être présents dans le prologue et en
particulier dans la DTD. Ils
peuvent aussi être placés dans le contenu de n'importe quel élément et
après l'élément racine. En revanche, ils ne peuvent jamais apparaître à
l'intérieur d'une balise ouvrante ou fermante. Un exemple de document
XML avec des commentaires partout où ils peuvent apparaître est donné
ci-dessous.
<?xml version="1.0" encoding="ISO-8859-1" standalone="no"?> <!-- Commentaire dans le prologue avant la DTD --> <!DOCTYPE simple [ <!-- Commentaire dans la DTD --> <!ELEMENT simple (#PCDATA) > ]> <!-- Commentaire entre le prologue et le corps du document --> <simple> <!-- Commentaire au début du contenu de l'élément simple --> Un exemple simplissime <!-- Commentaire à la fin du contenu de l'élément simple --> </simple> <!-- Commentaire après le corps du document -->
Les caractères spéciaux '<',
'>' et '&' peuvent
apparaître dans les commentaires. Il est en particulier possible de
mettre en commentaire des éléments avec leurs balises comme dans
l'exemple ci-dessous.
<!-- <tag type="comment">Élément mis en commentaire</tag> -->
Les instructions de traitement sont destinées
aux applications qui traitent les documents XML. Elles sont l'analogue
des directives #... du langage C qui s'adressent au
compilateur. Elles peuvent apparaître aux mêmes endroits que les
commentaires à l'exception du contenu de la DTD.
Les instructions de traitement sont délimitées par les chaînes de
caractères '<?' et '?>'. Les deux caractères
'<?' sont immédiatement suivis du nom XML de
l'instruction. Le nom de l'instruction est ensuite suivi du
contenu. Ce contenu est une chaîne quelconque de
caractères ne contenant pas la chaîne '?>'
utilisée par l'analyseur lexical pour déterminer la fin de
l'instruction. Le nom de l'instruction permet à l'application de
déterminer si l'instruction lui est destinée.
Bien que le contenu d'une instruction puisse être quelconque, il
est souvent organisé en une suite de paires
param="value"
Les fichiers sources DocBook de cet ouvrage contiennent des instructions de traitement de la forme suivante. Ces instructions indiquent le nom du fichier cible à utiliser par les feuilles de styles pour la conversion en HTML.
<?dbhtml filename="index.html"?>
Une feuille de style XSLT peut
être attachée à un document XML par l'intermédiaire d'une instruction de
traitement de nom xml-stylesheet comme
ci-dessous.
<?xml-stylesheet href="list.xsl" type="text/xsl" title="En liste"?>
L'entête XML
<?xml version=... ?> ressemble à une
instruction de traitement de nom xml avec des
paramètres version, encoding et
standalone. Elle utilise en effet la même syntaxe.
Elle n'est pourtant pas une instruction de traitement et elle ne fait
pas partie du document.
Quelques exemples minimalistes de documents XML sont donnés ci-dessous.
L'exemple suivant contient uniquement un prologue avec l'entête
XML et un élément de contenu vide. Les balises ouvrante
<tag> et fermante
</tag> ont été contractées en une seule balise
<tag/>.
Ce document n'a pas de déclaration de DTD.
<?xml version="1.0"?> <tag/>
L'exemple aurait pu encore être réduit en supprimant l'entête XML mais celle-ci est fortement conseillée. Le retour à la ligne après l'entête aurait aussi pu être supprimé sans changer le contenu du document.
Il est possible de répartir un gros document en plusieurs fichiers afin d'en rendre la gestion plus aisée. Il existe essentiellement deux méthodes pour atteindre cet objectif. Le point commun de ces méthodes est de scinder le document en différents fichiers qui sont inclus par un fichier principal. Les deux méthodes se différencient par leurs façons de réaliser l'inclusion.
La méthode la plus ancienne est héritée de SGML et elle est basée
sur les entités externes.
La méthode, plus récente, basée sur XInclude est à
utiliser de préférence aux entités externes. XInclude définit un
élément xi:include dans un espace de noms associé à l'URL
http://www.w3.org/2001/XInclude. Cet élément a un attribut
href qui contient le nom du fichier à inclure et un
attribut parse qui précise le type des
données. Cet attribut peut prendre les valeurs xml ou
text. Le fichier source principal de cet ouvrage
inclut, par exemple, les fichiers contenant les différents chapitres
grâce à des éléments include comme ci-dessous.
<book version="5.0"
xmlns="http://docbook.org/ns/docbook"
xmlns:xi="http://www.w3.org/2001/XInclude">
...
<!-- Inclusion des différents chapitres -->
<xi:include href="introduction.xml" parse="xml"/>
<xi:include href="Syntax/chapter.xml" parse="xml"/>
...
</book>
Le fragment de document contenu dans un fichier inclus doit être bien formé. Il doit, en outre, être entièrement contenu dans un seul élément qui est l'élément racine du fragment.
Il faut prendre garde au fait que certaines applications ne gèrent
pas XInclude. La solution est d'ajouter à la chaîne de traitement une
étape consistant à construire un document global entièrement contenu
dans un seul fichier. Le logiciel xmllint peut, par exemple, réaliser cette
opération. Avec l'option --xinclude, il écrit sur la
sortie standard un document où les éléments
xi:include sont remplacés par le contenu des fichiers
référencés. Cette option peut être combinée avec l'option
--noent pour supprimer les entités définies dans la DTD.
L'opération consistant à remplacer un élément
xi:include par le contenu du fichier doit mettre à
jour l'attribut xml:base de
l'élément racine du document dans le fichier. Cet attribut contient une
URL qui permet de résoudre les liens relatifs. Le chemin d'accès au
fichier doit donc être ajouté à la valeur de l'attribut
xml:base. Il faut, en particulier, ajouter cet
attribut s'il est absent et si le chemin d'accès est non vide. Le
chemin d'accès au fichier est récupéré dans l'attribut
href de l'élément
xi:include.
La mise à jour des attributs xml:base garde une
trace des inclusions et permet aux liens relatifs de rester valides. La
prise en compte des valeurs de ces attributs xml:base
incombe en revanche aux applications qui traitent le document et
utilisent ces liens.
Si chacun des fichiers introduction.xml et
Syntax/chapter.xml a comme élément racine un
élément chapter sans attribut
xml:base, le résultat de l'inclusion de ces fichiers
doit donner un document ressemblant à ceci.
<book version="5.0"
xmlns="http://docbook.org/ns/docbook"
xmlns:xi="http://www.w3.org/2001/XInclude">
...
<!-- Inclusion des différents chapitres -->
<chapter xml:id="chap.introduction" xml:base="introduction.xml">
...
</chapter>
<chapter xml:id="chap.syntax" xml:base="Syntax/chapter.xml">
...
</chapter>
...
</book>